

遅らばせながら、
Googleの日本語文字認識プログラム(nhocr)を
試してみました。
Google codeにソースが置かれています。
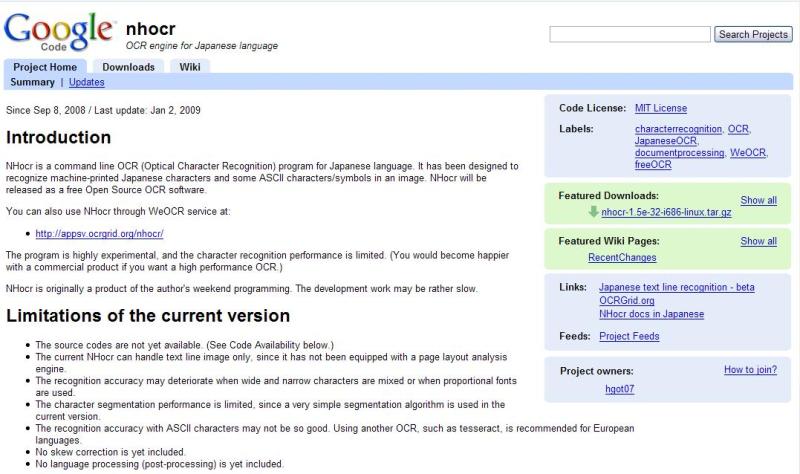
betaはこちらから
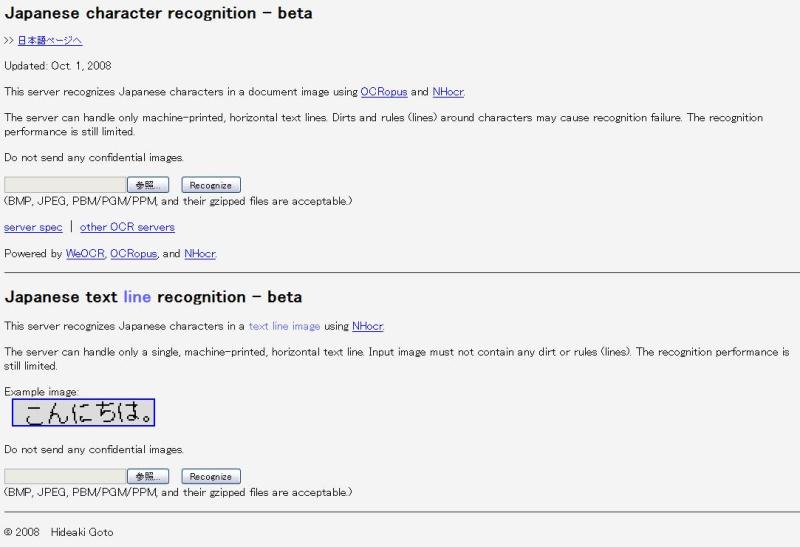
社員旅行用にと、実際に手元にあったパンフレットの
電子データを取り込んでみましたが・・・
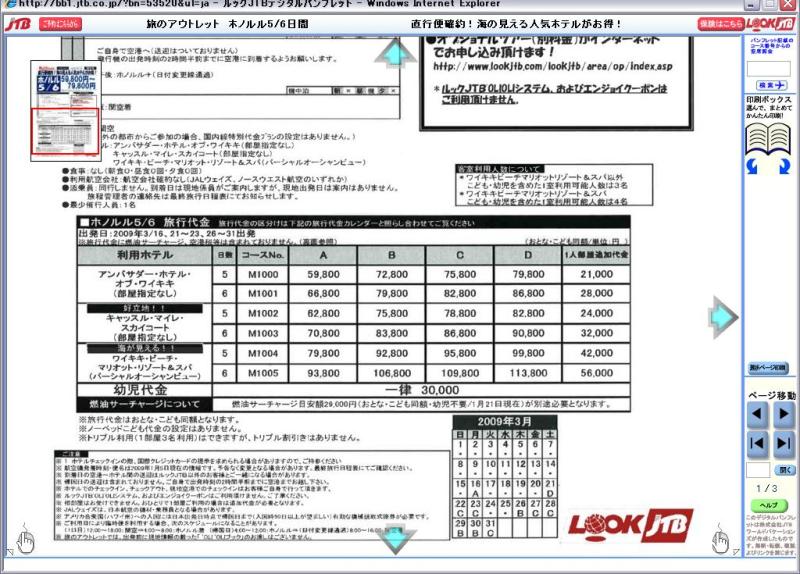
結果はこちら。

注意書きにもありましたけれど、
やはり、罫線や画像などが入れ込んであると、
認識できないようです。
まだまだ精度が低いのは仕方ありませんが、
英語版では、Google book Searchにも応用される程、
進化しているようです。
英語だけでなく、nhocrの精度がどんどん上がってくれば、
色んなところに応用できるんですけどね・・・
ま、あくまで開発者視点ではなくユーザー視点として
勝手なことばかり言ってますが・・・。
すいません。^^;